One of the challenges we often encounter is a large number of features available per observation - surprisingly, not the lack of them. We have a ton of information provided by our profiling solution (e.g. behavioral data, device and network information), transaction data provided by the client (what was bought, payment details, etc.) and data from additional external APIs - in total a couple of thousand features, even before we perform feature engineering.
For each transaction, we have to put client-provided data through hundreds - or in some cases even thousands - of feature engineering pipelines. At the same time, we have to get supplementary data from our profiling script and various internal and external APIs. In the next step, we have to perform predictions by multiple models. All of that has to be done in real-time, otherwise, customer conversion will suffer due to cart abandonment.
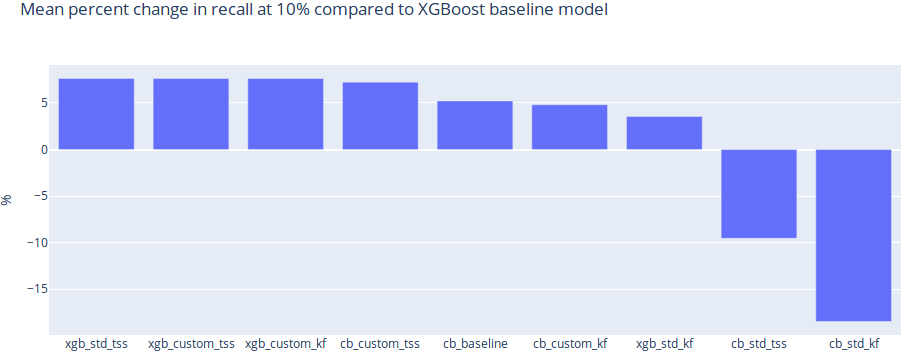
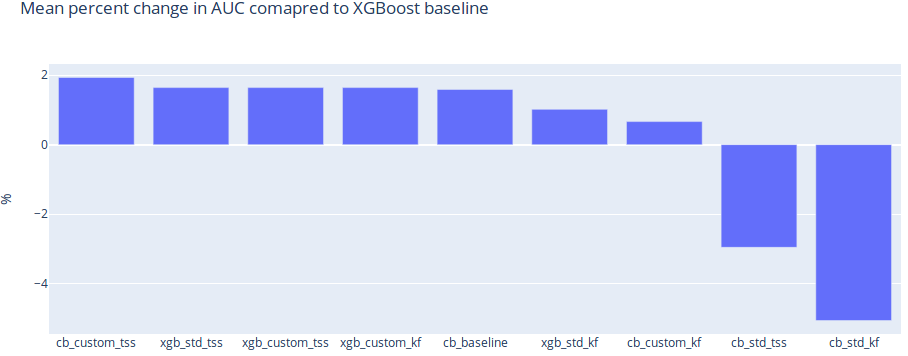
We wanted to test the qualitative performance of various XGBoost and CatBoost models, to see which one will better suit our needs. In this particular case, we are going to take a closer look at the last step of that process - prediction. Namely, we are going to use HyperOpt to tune the hyperparameters of models built using XGBoost and CatBoost. Having as few false positives as possible is crucial in the business of fraud prevention, as each wrongly blocked transaction (false positive) is a lost customer. Therefore, in this analysis, we will measure the qualitative performance of each model by taking a look at recall measured at a low percentage of traffic rejected.